


Hvis vi vil hente data ud af hjemmesider, bruger vi ofte web scraping i en eller anden form. Normalt betyder det, at vi automatiserer vores data-udtræk, og vi bruger ofte robotter, som vi programmerer, eller vi bruger andet specialværktøj.
Nogle gange kan vi dog nøjes med “håndværktøj” og lade det komplicerede grej ligge.
Her følger et skridt-for-skridt-eksempel på, hvordan man blot med en browser samt helt simple kommandoer i Word og Excel kan trække fine strukturerede data ud af en rodet webside. Opgaven er – i det konkrete tilfælde – at skaffe en liste med mange hundrede forskellige stillinger. Vi skulle bruge stillingerne for at kunne lave en søgemekanisme til denne valggrafik, som vi sammen med Symbiotisk Aps lavede for Avisen.dk.
På denne side http://www.lonstatistik.dk/job-a-til-z.asp er der remset alle stillingerne op, men de står rodet. Nogle stillinger består af et ord, nogle af to, tre eller fire. Sådan her ser det ud på siden:
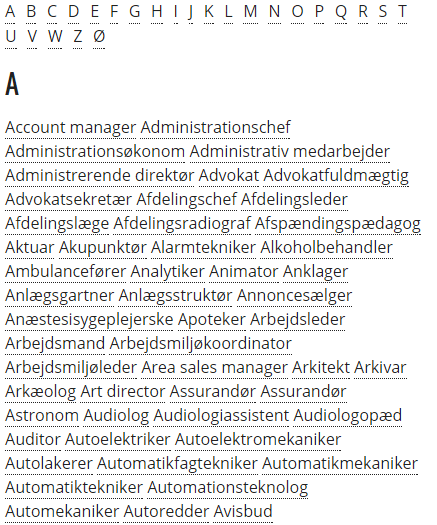
Og sådan fortsætter det så dernedad – for hvert bogstav i alfabetet.
Jeg starter med at kigge ind i sidens kode.
Her ser jeg, at stillingerne står i en stor klump. Jeg kopierer det hele over i et Word-dokument.
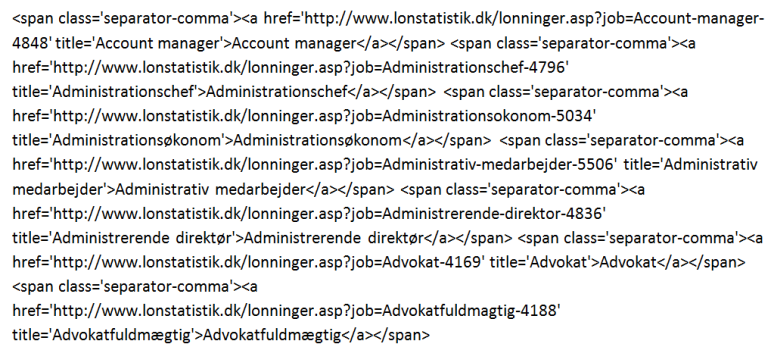
Det vil sikkert få mange programmører til at ryste på hovedet, men årsagen til, at jeg bruger Word i dette eksempel, er enkel: Stort set alle har programmet på deres computer, og Words søg/erstat-funktion er fleksibel og hurtig. Til nogle enkle renseopgaver er Word rigtig god.
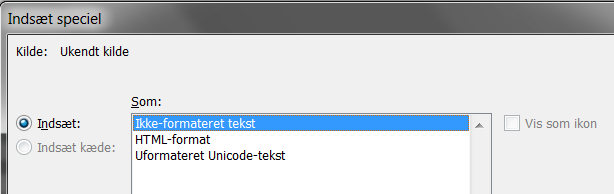
Når man sætter den kopierede kode ind i Word, er det vigtigt, at koden indsættes som uformatteret tekst. Vi vil ikke have en masse hyperlinks at slås med. For at få uformatteret tekst, vælg Indsæt speciel… og “Ikke-formateret tekst”.
Find mønsteret
Et af de vigtigste værktøjer i al scraping er at se grundigt på data og se, om man kan finde en form for mønster i de data, der skal scrapes og måske senere renses. Kan man finde et mønster, er man allerede langt.
Ser man i dette tilfælde på tekstblokken, der blev kopieret ind i Word, er det tydeligt, at der for hver stilling, der er med i datasættet, er en speciel struktur. Stillingen, vi vil have trukket ud, er her markeret med rødt:

Det specielle går på, at omkring hver stilling starter kodeblokken med “<span class=’separator-comma’>”. Og efter den stilling, vi gerne vil have trukket ud, slutter hver kodeblok med “</a></span>”.
Jeg starter med at skabe lidt mere struktur i data. Så er det også lettere at se, om den opbygning, vi mener at have fundet, nu også er gennemgående i hele datasættet.
Jeg vil have al koden, der hører til hver stilling, til at stå på en linje for sig. Så jeg erstatter </a></span> (den afsluttende del af koden) med et afsnitstegn. Det gør man sådan her i Words “søg og erstat”-funktion:
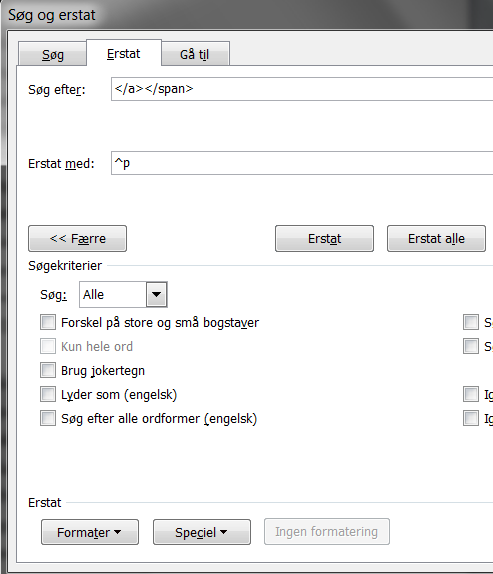
Ved man ikke, hvordan afsnitstegnets kode skal skrives, kan man finde den under knappen med “Speciel”.
Efter der er sat et afsnitstegn ind, ser Word-dokumentet nu sådan her ud:
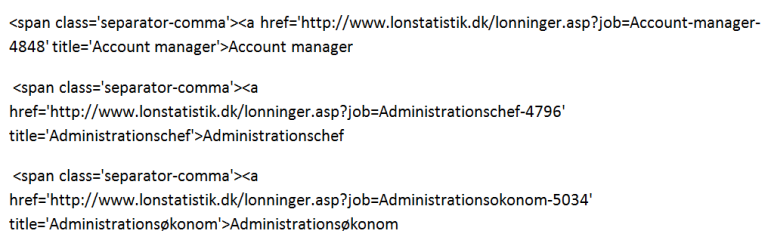
Det er tydeligt, at der er noget, der går igen – uændret – for hver eneste stilling. Nemlig al koden fra starten og hen til, hvor stillingen bliver nævnt efterfulgt af et id-nummer:
“<span class=’separator-comma’><a href=’http://www.lonstatistik.dk/lonninger.asp?job=”
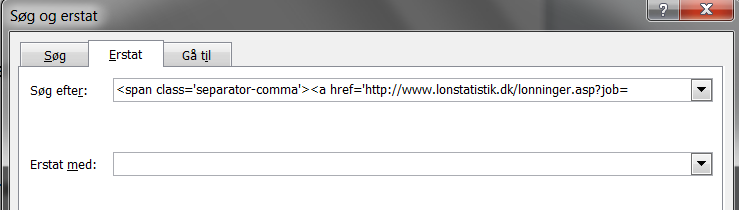
For at fjerne al denne unyttige kode fra dokumentet, bruger vi søg/erstat. Jeg søger på denne kodestreng og erstatter ikke med noget. Jeg lader altså feltet ud for “Erstat med” stå tomt. Det betyder, at det, jeg har søgt på, blot slettes:
Teksten ser pænere ud nu.
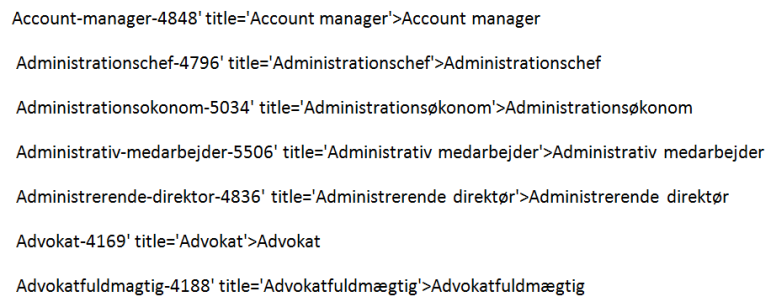
Jeg kopierer den og sætter den ind i et regneark. Nu er jeg færdig med at bruge Word. Resten af rensningen foregår i regnearksprogrammet.
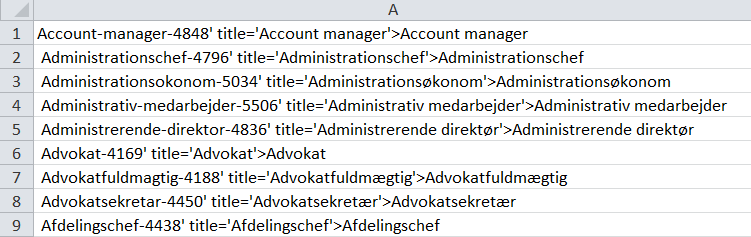
Her er det fornuftigt at gå ned gennem hele dokumentet for at se, om rensningen indtil nu er lykkedes. Det er den, men det viser sig, at hver gang, der kommer stillinger med et nyt forbogstav, kommer der en linje kode, der skal renses på en anden måde end resten. Og der er også et enkelt sted i regnearket, hvor nogle rækker blot skal slettes, fordi der ligger en annonce inde i rækken af stillinger.

For at få isoleret alle rækkerne, der indikerer nyt bogstav, skal man blot sortere data i regnearket. Så vil rækkerne, der starter med <p> komme enten øverst eller nederst.
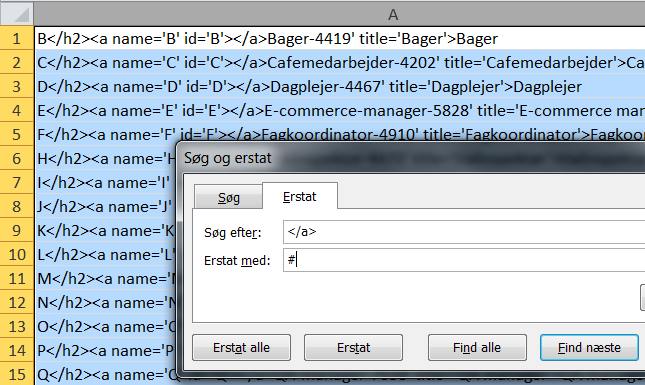
De kan så renses. Først ved at søge på ” <p><span class=’icon-arrow-right2′></span> <small><a href=’#top’>Till toppen</a></small></p><h2>” og erstatte med ingenting. Dernæst søge på </a> og erstatte med et tegn, der ikke optræder i data – her bruger jeg tegnet #:
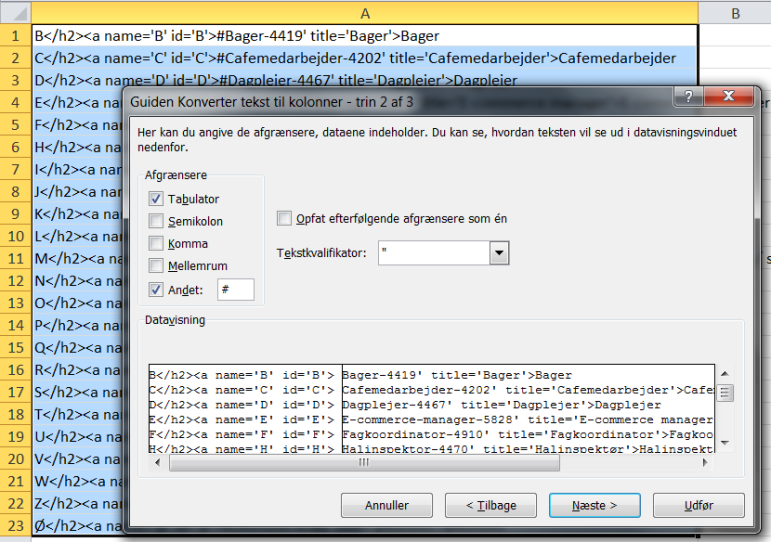
Endelig bruges værktøjet “tekst til kolonner” for at få skilt indholdet i to kolonner:
Nu har vi så en lang liste med alle stillinger. Vi skal kun skal bruge det, der står til højre for den skarpe parantes.
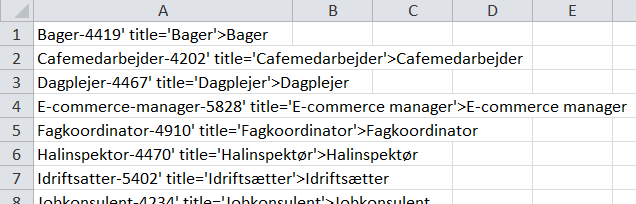
Adskillelsen klares nemt ved igen at bruge regnearkets tekst-til-kolonner-værktøj:
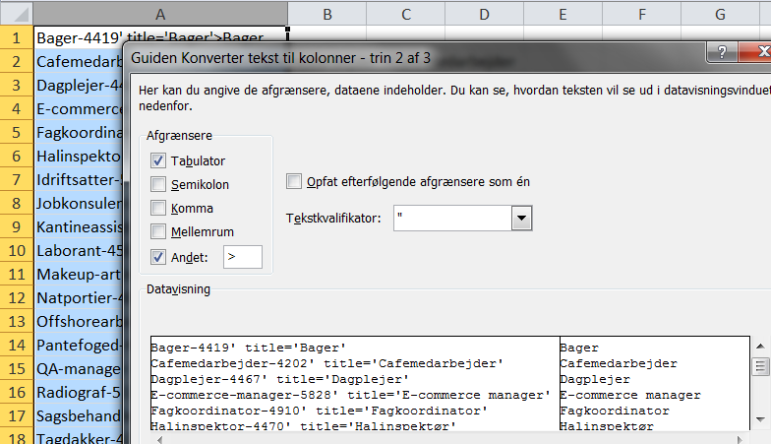
Og tilbage er den rensede liste:
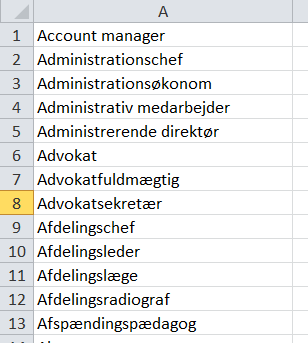
Selvfølgelig er det ofte mere kompliceret at trække data ud af websider. Men nogle gange kan man som demonstreret her klare sig med de helt almindelige programmer, vi stort set alle har på computeren.
Du kan lære mere om webscraping og rensning ved at gå på et af vores kurser. Vi underviser i web scraping ved hjælp af Python eller ved hjælp af det nemmere Helium Scraper.
No comments yet.