


April 2018: Nedenstående artikel fra august 2014 er skrevet kort efter, at vi havde premiere på vores interaktive “Navnehjul”. Artiklen giver et indblik i udviklingsarbejdet og vores overvejelser. Ultimo marts 2018 er Navnehjulet udkommet i en ny udgave – med opdaterede data og med tre nye datatyper: Millionærtæthed, skatteindbetaling og favorit-bilmærke. Facebook har lavet ændringer, så vi ikke længere kan tilbyde mange forskellige delingstekster, som vi oprindeligt kunne. I dag kan Navnehjulet kun indeholde én delingstekst, hvor vi i princippet sidste gang havde 17 forskellige delingstekster for hvert eneste navn, der kunne søges på (og som vi beskriver nedenfor).
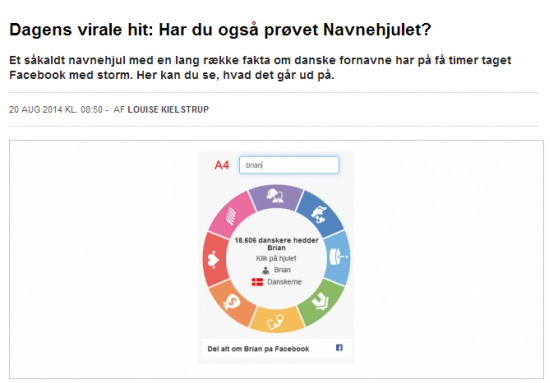
August 2014: “Dagens virale hit”. Sådan skrev TV2-sitet beep onsdag morgen, efter at Ugebrevet A4 sidst på eftermiddagen dagen før havde skrevet en opdatering på Facebook om vores fælles “barn” – Navnehjulet, der viser en række statistiske data for godt 2300 forskellige fornavne: Hvor kriminel er en Brian i forhold til gennemsnitsdanskeren (meget mere), hvad er gennemsnitsalderen på en Adolf (71 år), hvilket job har en Shila typisk (frisør), hvor finder vi oftest en Jürgen (Aabenraa), og tjener en René godt (ja, i snit tjener ingen så meget som René).
Navnehjulet blev lynhurtigt spredt via Facebook. Bare inden for det første døgn havde navnehjulet haft 650.000 besøg. Da trafikken var heftigst, var der 57.000 sidevisninger i timen. Søndag var hjulet blevet delt over 8000 gange på Facebook, og 14.000 havde kommenteret.
Et års arbejde
Der er gået et år, siden vi første gang begyndte at tale om en form for en navne-app, der skulle sammenligne fornavne og privatøkonomi. Det skete i et mødelokale hos Ugebrevet A4, der holder til i LO’s domicil på Islands Brygge. Her diskuterede bl.a. redaktør Jan Birkemose, redaktionschef Carsten Terp, teknisk ansvarlig Mads-Emil Sejrbo Lidegaard og jeg ideer til projekter, vi kunne lave sammen.
En af dem, vi først blev enige om, skulle prøves af, var “en præsentation, der bygger på navne”, som jeg skrev i referatet. Og jeg understregede, at vi også var enige om, “at der skal være et ”mobbe” eller ”drille”-element. Noget, der gør det sjovt at dele indholdet med andre.”
Da hjulet blev opfundet
Vi mødtes igen og diskuterede navneprojektet, og Jan Birkemose foreslog hurtigt, at vi kunne bruge et hjul som centrum. Han havde lavet et billede og lagt det ind på mobilen, så vi kunne se, hvad han forestillede sig.
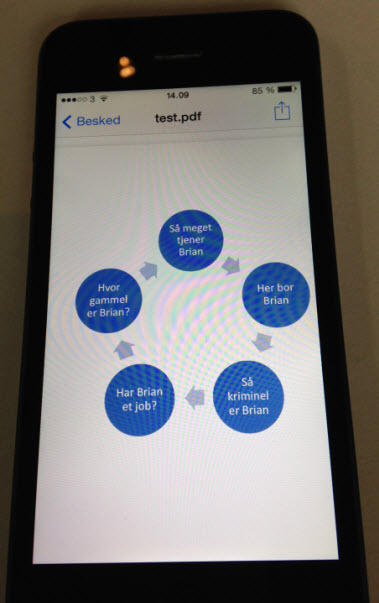
At den allerførste skitse blev vist gennem en mobils display, var ingen tilfældighed. Mobile-first var princippet, og over halvdelen af alle sidevisninger af hjulet er da også sket på en mobiltelefon.
De første skitser
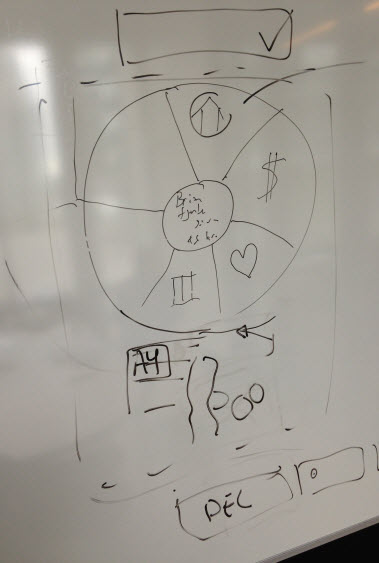
Under den første navnehjul-brainstorm brugte vi mødelokalets whiteboard til at diskutere de første ideer om, hvordan sådan et hjul kunne virke. Og det ses måske ikke tydeligt, men en stor del af det færdige hjul var allerede med på de første skitser.
Over de kommende måneder blev der udvekslet mange mails mellem især Jan, Mads-Emil og jeg. Efterhånden blev også Chase Davis, vores amerikanske samarbejdspartner involveret. Chase Davis er medejer af firmaet HotType Consulting og er deputy editor på New York Times’ Interactive News Desk.
Browserløsning og design
Vi blev enige om, at vi ikke ville lave en app. Navnehjulet skulle kunne åbnes i en browser og skulle tilpasses, så den selvfølgelig ville virke på alle platforme. Hurtigt blev grafisk designer Pia Seidler involveret, og hun kom med en stribe oplæg, som Navnehjulets udseende blev indrettet efter.


Den grundlæggende funktionalitet var hurtigt på plads. Øverst en søgemulighed. I midten lå hjulet med en række valg. I midten af hjulet noget tekst om det aktuelle valg. Og nederst en form for en opsamlende “rapport”, der ville gro, efterhånden som der blev klikket på hjulet.
Men det grundlæggende er én ting. Noget andet er, hvordan det hele spiller sammen. Hvad sker der helt konkret, når man klikker på hjulet? Sker der noget med søgefeltet imens, og hvad med rapporten?
15 Facebook-deleknapper pr navn
Vi var enige om, at Navnehjulet selvfølgelig skulle spredes via delinger på sociale medier. Men var én deleknap nok?
Afgjort ikke, mente A4, og vi brugte lang tid i foråret på at skyde os ind på de bedste måder at gøre det på.
Vi ville også gerne kunne dele på mange forskellige måder. Derfor er der for de fleste navne hele 15 forskellige deleknapper og -tekster.
Så man helt overordnet kan dele alt om et navn:
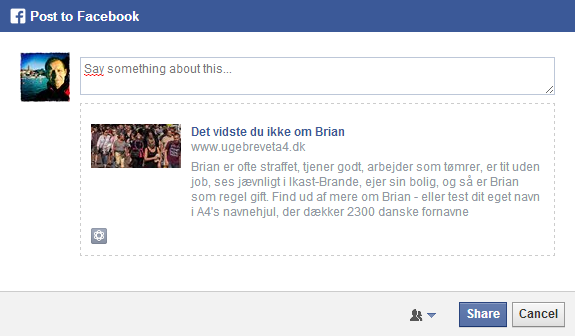
Eller man kan dele for hvert enkelt aspekt – bolig, parforhold, job, geografi eller som her – straf:
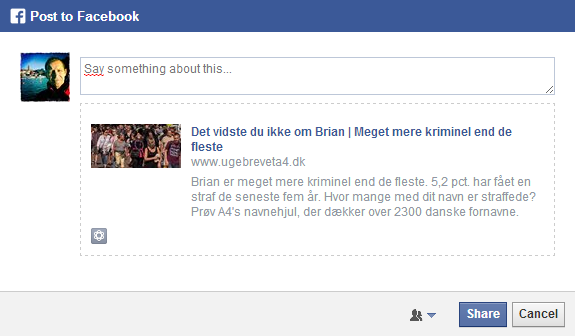
Som vi har beskrevet i sitets dokumentation, stammer alle oplysningerne fra Danmarks Statistik. Vi betalte for alle data og havde en løbende dialog med en chefkonsulent, som selv blev meget optaget af opgaven, og som gav gode, brugbare bud på, hvordan data kunne indrettes.
Jeg modtog en stribe regneark i slutningen af oktober og begyndte et større analyse- og beregningsarbejde.
196.000 forskellige tekster
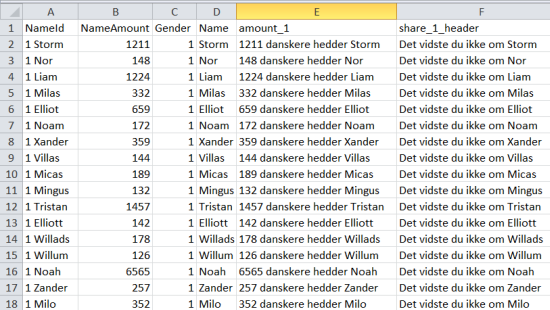
Vi forudså, at der kunne komme megen trafik, og vi gik efter en løsning, der kunne køre så hurtigt som muligt, og som ikke krævede beregninger, hver gang en bruger trykkede på hjulet. Derfor lavede jeg alle beregninger (fx andel straffede, andel ledige etc.) på forhånd, og jeg skrev alle de tænkelige tekster, der kan vises i hjulet og rapporten på forhånd. Al information blev kombineret i ét stort regneark på over 90 kolonner og over 2300 rækker. I alt blev det til godt 196.000 forskellige tekstelementer; til at blive vist i midten af hjulet, til at blive vist i rapporten og til at blive vist som facebook-delingstekster.
Indholdet af regnearket blev konverteret til JSON-formatet, og opgaven for Chase Davis var først og fremmest at programmere selve hjulet og at programmere det, så det kunne trække de relevante tekststumper op fra denne flade fil, vi endte med at lægge hos Amazon S3.
Et samarbejde som dette, hvor vi sad tre-fire forskellige steder, giver rig mulighed for misforståelser. Når man diskuterer udseende og funktionalitet, slår ord ikke altid helt til, og flere gange lavede vi dummyer i photoshop etc., som vi mailede til hinanden for mere konkret at kunne demonstrere, hvad det var, vi hver især tænkte på.
Valg og fravalg
Vi havde også en del ideer undervejs, som vi fravalgte eller i første omgang nedprioriterede. Fx indbyggede vi ikke deling via Twitter og mail. Til gengæld satsede vi på at gøre facebook-deling effektiv og nem.
Vi havde også oprindeligt tænkt, at hjulet skulle kunne vise et kort, der viser, hvor det fx er mest almindeligt at løbe på en person med et bestemt navn. På kortet her viser de mørke farver fx, hvor det er mest almindeligt at møde en Peter (navnet, som flest mænd pt har):
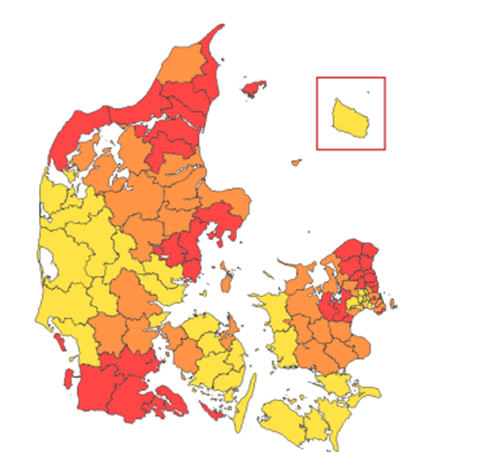
Det fravalgte vi også i første omgang – vi nøjes med at nævne de tre områder, hvor frekvensen er højest.
Modtagelsen
Den sidste lange periode op til lanceringen i denne uge har især handlet om at få kortet til at virke korrekt, når det blev afviklet fra Ugebrevet A4’s site. Data ligger fortsat hos Amazon. Vi har forberedt os grundigt, så alt, brugerne foretager sig med Navnehjulet, kan analyseres bagefter – hvilke navne er oftest søgt på, hvilken del af hjulet klikkes der oftest på etc. Og så har vi testet for fejl – og fundet fejl – som vi så har rettet.
Men anstrengelserne bar frugt. Sitet blev færdigt. Det blev lanceret. Trods overvældende trafik gik det ikke ned eller blev langsomt. Det blev delt, kommenteret og rost.
Tilbage er nu overvejelserne om, hvordan medier kan bruge den slags indhold til fx at få trafik til journalistikken, få sign-ups til nyhedsbreve og øge den kommercielle værdi af de mange klik.
Hej Tommy
Tak for forklaringer og ros herfra til Navnehjulet.
Jeg har to spørgsmål:
1) Hvorfor har I valgt at bruge gennemsnitsindkomsten i stedet for medianindkomsten?
2) Hvordan har I defineret forskellen mellem “meget mere” og mere (og meget mindre og mindre), når I fortæller, hvor personen befinder sig mellem sine navnefæller?
De bedste hilsner fra Thomas
Hej Thomas
Tak for ros.
1) Det er det samme dilemma hver gang: En median giver måske det mest korrekte tal, men et gennemsnit er lettere at forstå. Her prioriterede vi forståelsen.
2) Det svinger fra område til område. Vi har lagt en “buffer” ind omkring gennemsnittet, så dem, der lander tæt på, også bliver kategoriserede som gennemsnitlige. “Mindre” giver sig selv. Så er der “mere” og “meget mere”, hvor vi har prøvet at lave nogle snit, der gav mening i forhold til de konkrete tal.